Goal: Implementation of a distributed microkernel operating system
Phase 1 (6-12 months):
Phase 2 (12-18 months):
The project will be open source and will have a website for documentation.
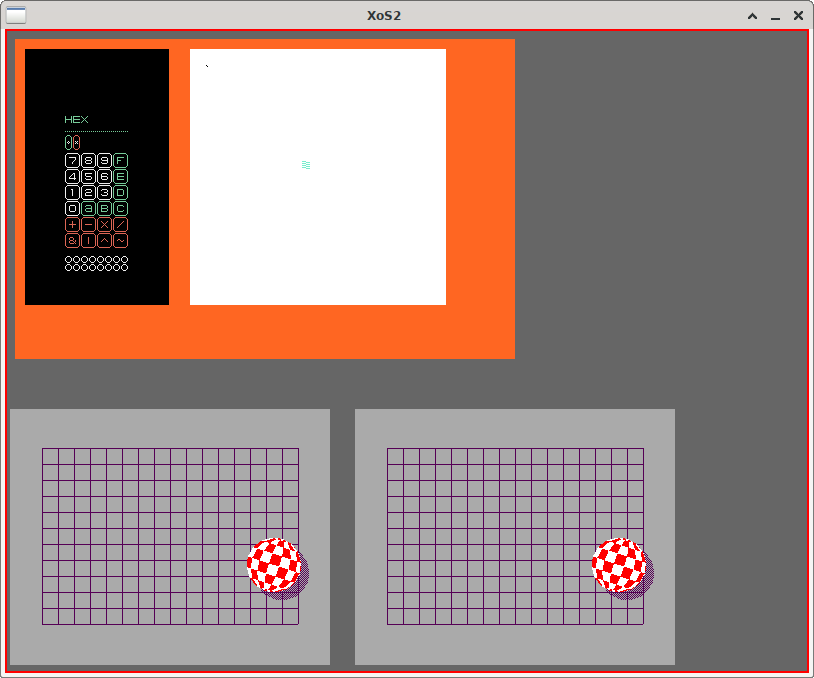
Prototypes already developed using the proposed architecture:
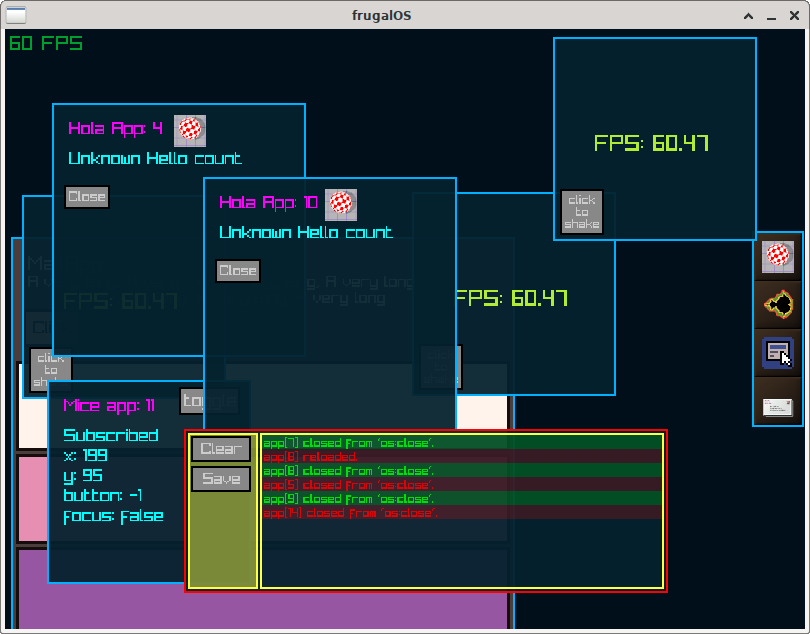
This project is an application of our mission and is, above all, educational in nature. We do not have much material, especially in Portuguese, on this subject.
Create an environment for exploring new ideas, where it is possible for a single individual to understand the whole, and, if they so desire, make changes to meet their needs.
That's one of the first questions I hear when I talk about the project.
The answer is quite simple: to reduce complexity and potentially energy waste.
Modern operating systems are huge projects and serve a wide variety of use cases.
The goal is not to make a “better Linux” or “better Windows,” but to create a simple alternative to solve simple problems.
Creating an operating system that allows us to perform common everyday tasks, such as reading emails, exchanging messages, and surfing the internet using modest hardware is not impossible to implement.
I am not convinced that we have exhausted the possibilities of software design and implementation. Our field is still too young to make such a claim. With this project, I hope to explore ideas that have been tested in the past and perhaps discover new ways of creating software.
In the following sections, I will provide more details about the motivations and inspirations for this project.
What I am about to say probably isn't big news for those who work in IT, especially in software development. The increase in the complexity of tools/methodologies over the last decade is somewhat frightening.
For people outside the field (and perhaps some inside it), this is normal, since problems are becoming increasingly complex, right?
I'm not so sure about that. Let me rephrase that question a little better.
Fred Brooks, in his famous article No Silver Bullet - Essence and Accident in Software Engineering, defines this interesting concept of essential and accidental complexity in software development.
In summary:
Every problem has a certain level of accidental complexity. This complexity is evident in the tools we use to solve the problem: programming languages, frameworks, task organization, etc.
Accidental complexity is inevitable. It must be mitigated so that the focus is on the essential complexity of the problem at hand.
It is difficult to pinpoint the “culprit” for this accidental increase in complexity, but I will take a chance and list a few points:
1. Software reuse
We learn early on that software reuse is a good thing and should be one of the goals for a successful project. Unfortunately, it's not that simple. Indiscriminate reuse causes us to create hundreds of dependencies, and managing those dependencies increases accidental complexity.
2. Speed over quality
We have come to value speed over quality. This also contributes to the previous point.
3. IT market valuation
Developing software is a difficult task. It requires skilled labor, which is increasingly scarce. Our current dependence on software further accentuates this point. However, there is a hidden factor that I consider relevant in this equation. We use excessive accidental complexity as a justification (often unconscious) for the high cost of IT services. This makes it seem justified and even desirable in a way, so that this high cost can continue.
4. Monopoly Large IT companies dictate most of the rules and trends in technologies used in the field. They have little interest in changing the status quo, and as a result, the accidental complexity of our tools continues to increase.
We are indeed solving more complex problems than we were 10-20 years ago. That does not mean that we are better at solving problems than we were 10-20 years ago. My feeling is quite the opposite: with each passing year, we are sinking deeper into this accidental complexity, and our problem-solving ability is going down with us.
Today, more and more people/organizations are concerned about:

My perception is that over the next ~20 years, we will see a rapid movement toward decentralization, with IT solutions becoming more regionalized. The current model of monopoly by large IT companies will be diluted.
To keep up with this trend, we must rethink the tools and methodologies we use today to develop and provide solutions.
As inspiration and a model for implementing this project, I will use what I call the “Wirth Philosophy.” Niklaus Wirth was one of the pioneers in applying simple and powerful techniques to solve problems in the field of IT. He is best known for creating the Pascal programming language, but his most admirable work is the creation of the programming language and operating system of the same name: Oberon.
Make it as simple as possible, but not simpler. (A. Einstein)
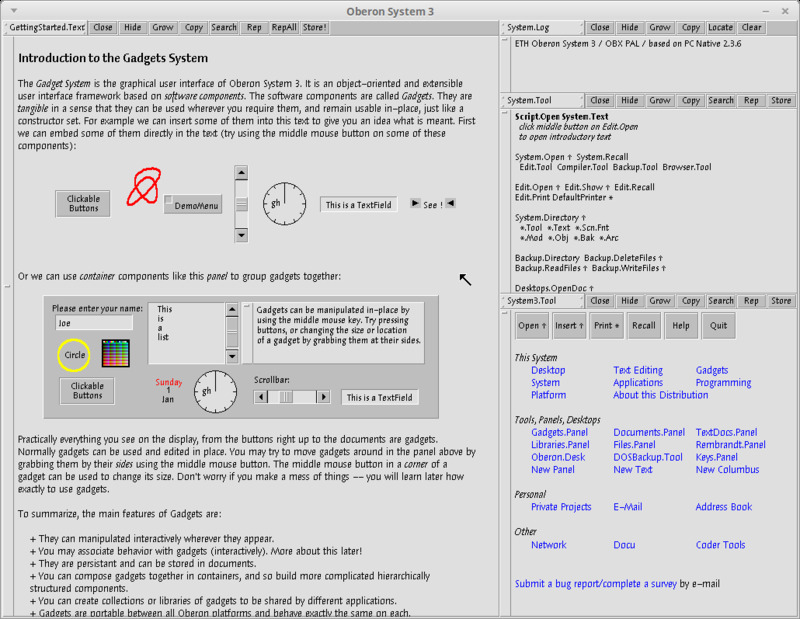
As mentioned earlier, Oberon is the name of both a programming language and the operating system developed in it.
Oberon as a programming language has a minimalist approach to its construction. It uses few but powerful abstractions, and its syntax can be easily learned in a few hours.
Within these abstractions, we can highlight:
Oberon as an operating system has some rather original ideas. It uses a document system that is pervasive throughout the system, allowing any document to be a program and/or invoke/use other programs.
Implements multitasking through a task scheduling/execution mechanism and also through message exchange.
The original implementation consists of the compiler and operating system (written in the language itself), preserving a code base of around 10,000 lines of code.
Erlang is a functional programming language created in the 1980s by Erikson. It comes with a virtual machine (OTP) that is highly fault-tolerant and scalable. It uses a distributed architecture where we can create multiple nodes running applications and set up clusters to scale problem solving horizontally.
The idea is that each task can be executed in a separate process and that these processes exchange messages with each other. These processes are called actors.
The actor model is a computational model that uses this entity called an actor as its main building block.
In response to a message received, actors can:
Another interesting feature is that actors from different nodes can exchange messages transparently, as if they were running on the same node.